Multi Data Center Replication (1st phase)
Apr 11, 2014If you look at the big idea at LeoFS, what we're really focused on is high scalability, high availability and high cost performance ratio because as you know, unstructured data have been exponentially increasing day by day, so we need to build global scale storage system at low cost.
I've been considering how to realize LeoFS's multi data center replication more simply without SPOF - Single Point Of Failure and degrading the performance.
I introduce how we were able to build a multi cluster storage system.
Set configuration of clusters
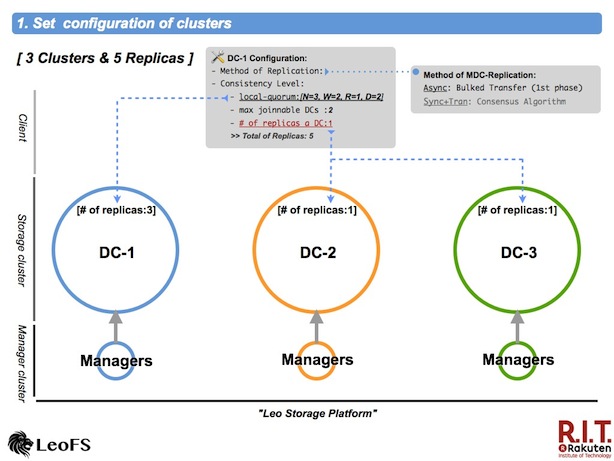
First, it is necessary to configure consistency-level, max number of joinable clusters and number of replicas a data center both the local cluster and the remote cluster(s).
The 1st phase of multi data center replicaion also supported asynchronous replication between clusters
Join each cluster
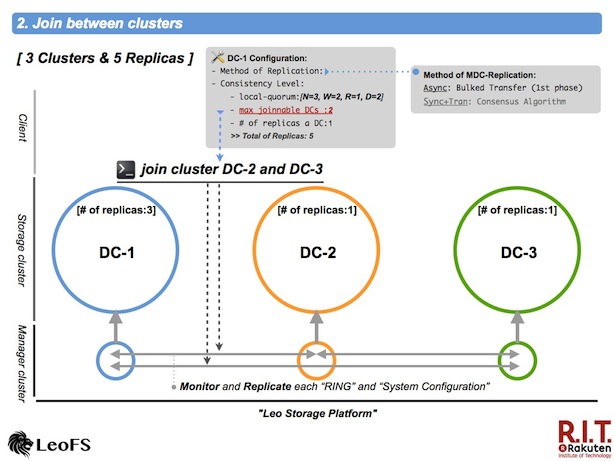
Next, execute the join-cluster command on the manager-cosole in order to communicate between the clusters. It is necessary to take notice of the configuration - max number of joinable clusters. When the set value is exceeded, leo_manager will reject your request.
Finally, confirm whether the preliminary work is complete correctly with the cluster-status command.
Replication - 3 replicas are stored into the local cluster
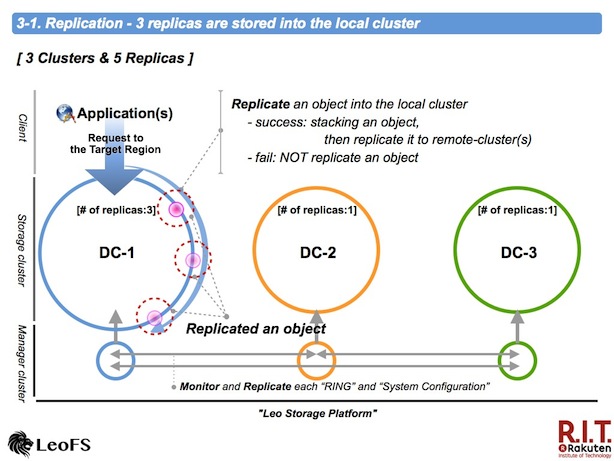
As I mentioned, we adopted aynchronous-replication as the way of the multi data center replication between clusters at the 1st phase.
leo_storage is prior to replicate an object in the local cluster. If successful that, it is stacked into a container in order to realize the bulk transfer. On the other hand the process was fail, it is not stacked.
Replication - Stacking objects into leo_storage(s)
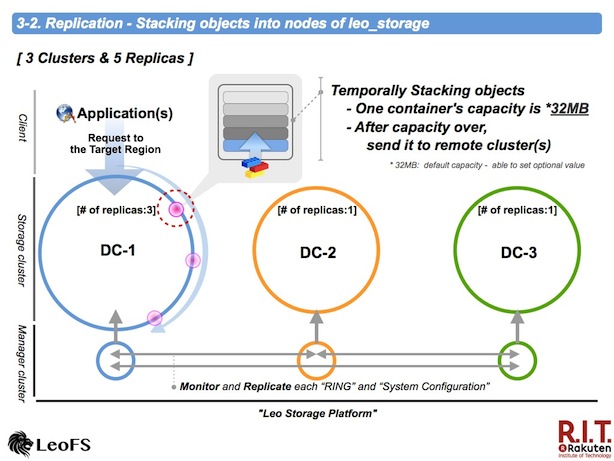
An object with a metadata is stacked into a container in order to replicate stacked objects to remote cluster(s).
The default capacity of the stacking object container is 32MB. the stacked object is transferred after the capacity over. Also, when not received requests for 30sec, the objects in the container by stacked now is transferred. You're able to rewrite both values.
Replication - Transfer stacked objects to remote cluster(s)
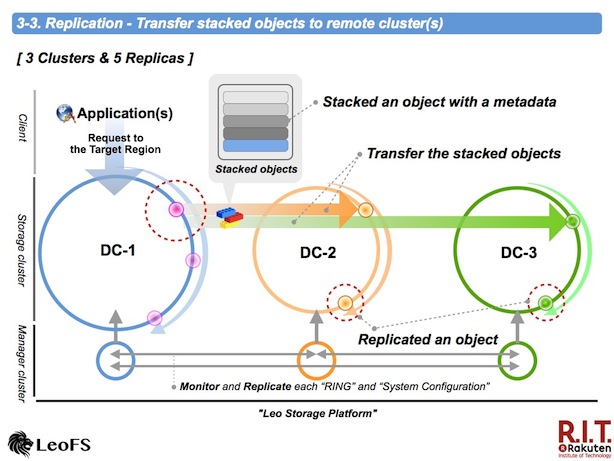
A stacked objects is compressed with LZ4 in order to reduce network traffic. Destination nodes - primary and secondary are randomly chosen from nodes of a destination cluster in order to restrict unbalanced requests.
A accepted node uncompresses a received file - a compressed stacked objects, then original objects are replicated into its cluster.
Comapare replicated objects and fix inconsistent objects
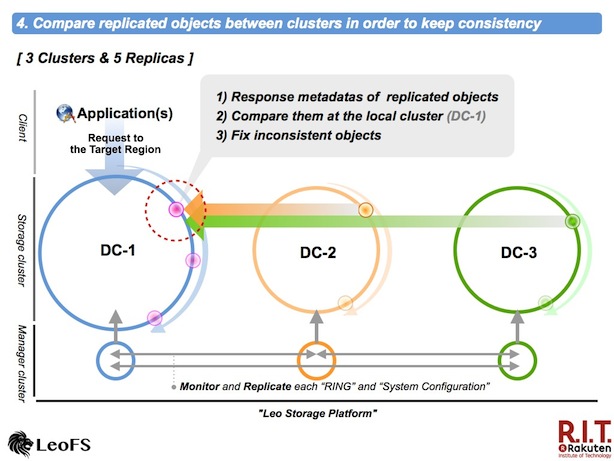
The node of the local cluster receives metadatas of trasfered objects, then compare them between clusters in order to find and fix inconsistent objects eventually. Inconsistent objects are stacked into the container, again.
Wrap up
We designed this mechanism/function without the performance degration and the availability but it is now 1st phase. So we're going to improve and increase it, going forward.